
Hallo iedereen,
ik zit met een belangrijke opdracht voor school, maar geraak er helemaal niet wijs uit. Hopelijk kunnen jullie me helpen. Volgens dat ik heb kunnen opstellen bekom ik volgende vgl:
A*(tijdstip1)+B*(tijdstip2)+C*(tijdstip3)+D*(tijdstip4)=verbruik*(som tijdstippen)
Dus ik heb de tijdstippen gekregen, en ook het verbruik. En dit voor 100 verschillende vgl'en. Dus als ik dit in een matrix wil steken heb ik meer vgl dan onbekenden en dus geen oplossing. Maar het is de bedoeling dat ik waarden uitkom voor A,B,C en D die ervoor zorgen dat bijna elke vgl perfect uitkomt. Weten jullie hoe ik dit zou kunnen aanpakken? Jullie zouden mij echt vooruit helpen. Bedankt
Belangrijke opdracht

Re: Belangrijke opdracht
Je kan werken met multipele lineair regressie, zie bv
http://en.wikipedia.org/wiki/Regression ... near_model
Hierbij maak je de fout e = epsilon minimaal, dwz: de som van (de kwadraten van (de verschillen tussen alle werkelijke waarden en de modelwaarden)) wordt minimaal.
Dit is multipel omdat je werkt met meer dan 1 onafhankelijke variabele: t1 t/m t4.
Kijk eerst eens naar een vereenvoudigde versie van jouw probleem:
Deze gegevens wil je met lineaire regressie modelleren in de vorm:
A*t1 + B*t2 + C*t3 = v*(t1+t2+t3)
Wat is in dit geval de matrix X?
Wat is hier de vector y?
Wat is de vector^{-1}\cdot X^T \cdot y)
Wat zijn dus de waarden van A, B en C volgens dit model?
http://en.wikipedia.org/wiki/Regression ... near_model
Hierbij maak je de fout e = epsilon minimaal, dwz: de som van (de kwadraten van (de verschillen tussen alle werkelijke waarden en de modelwaarden)) wordt minimaal.
Dit is multipel omdat je werkt met meer dan 1 onafhankelijke variabele: t1 t/m t4.
Kijk eerst eens naar een vereenvoudigde versie van jouw probleem:
Code: Selecteer alles
t1 t2 t3 v
105 45 35 4.92
60 23 12 4.53
89 56 100 6.73
45 24 67 7.35
A*t1 + B*t2 + C*t3 = v*(t1+t2+t3)
Wat is in dit geval de matrix X?
Wat is hier de vector y?
Wat is de vector
Wat zijn dus de waarden van A, B en C volgens dit model?
Re: Belangrijke opdracht
Bedankt voor de reactie 
Dus als ik het juist heb, kom ik het volgende uit:
Matrix X
105 45 35
60 23 12
89 56 100
45 24 67
Vector y
4,92*(105+45+35)
4,53*(60+23+12)
6,73*(89+56+100)
7,35*(45+24+67)
Dus de vector beta is:
3,135
4,256
11,300
A = 3,135
B = 4,256
C = 11,3
Klopt dit?
Echt bedankt!! Nu kan ik eindelijk verder
Dus als ik het juist heb, kom ik het volgende uit:
Matrix X
105 45 35
60 23 12
89 56 100
45 24 67
Vector y
4,92*(105+45+35)
4,53*(60+23+12)
6,73*(89+56+100)
7,35*(45+24+67)
Dus de vector beta is:
3,135
4,256
11,300
A = 3,135
B = 4,256
C = 11,3
Klopt dit?
Echt bedankt!! Nu kan ik eindelijk verder
Re: Belangrijke opdracht
Klopt.
Deze waarden heb je hierboven al gevonden:
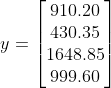
En volgens je model vind je de benaderde waarden:
vind je de benaderde waarden:
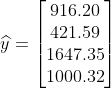
Voor alle 4 onze vergelijkingen geeft dit model dus een redelijke overeenkomst met de werkelijke waarde.
Let wel: we hebben hier een lineair model gekozen met de gebruikelijke foutmaat.
Doorgaans volstaat dit, maar dit betekent niet dat dit ook altijd het beste model voor elke toepassing is.
Deze waarden heb je hierboven al gevonden:
En volgens je model
Voor alle 4 onze vergelijkingen geeft dit model dus een redelijke overeenkomst met de werkelijke waarde.
Let wel: we hebben hier een lineair model gekozen met de gebruikelijke foutmaat.
Doorgaans volstaat dit, maar dit betekent niet dat dit ook altijd het beste model voor elke toepassing is.
Re: Belangrijke opdracht
En hoe bepaal je dan welk model het beste aansluit? En zo de fout het kleinste is?
Re: Belangrijke opdracht
Dat ligt ingewikkeld.
Stel we hebben de volgende meetgegevens:
en we willen y gaan voorspellen als functie van x.
Je kan dit doen met regressie-analyse (zie bv http://nl.wikipedia.org/wiki/Regressie-analyse) vergelijkbaar met wat we hierboven gedaan hebben.
Je zoekt dan de lijn y = Ax + B die zo goed mogelijk door de meetpunten gaat.
Je vindt in ons geval y = 2x + 2.67
Als je kijkt naar onze x-waarden vind je de model-waarden ym:
De som van de afwijkingen in het kwadraat = som (y-ym)^2 = (1/3)^2 + (2/3)^2 + (1/3)^2 = 2/3.
Een rechte lijn waarvoor deze foutensom kleiner is bestaat niet.
Voor deze foutensom is dit de optimale lijn.
Maar niemand zegt dat we verplicht zijn om deze foutenmaat te hanteren. Je zou bijvoorbeeld ook naar de som van (de absolute waarden van) de afstand van elk punt tot de lijn kunnen kijken.
Een tweede punt is: waarom zou het model een lineair model moeten zijn, dus in de vorm ym = Ax + B?
Stel we kiezen een kwadratisch verband: ym = Ax^2 + Bx + C.
Je vindt dan als best passende parabool ym = x^2 - 2x + 6.
De foutensom is nu nul! (ga maar na voor x = 1, 2 en 3)
Hoewel de foutensom nu nul is, hoeft dit echter niet het model te zijn dat het proces dat je bestudeert het beste beschrijft. Als je bijvoorbeeld meer meetpunten zou hebben, zou er heel goed uit kunnen komen dat de beste rechte lijn dan toch beter past dan de beste parabool.
Als je domeinkennis hebt, dus weet volgens welk verband je proces verloopt, bv lineair, kwadratisch, exponentieel etc, dan kies je natuurlijk dat betreffende model.
Weet je het niet, dan kies je doorgaans het meest eenvoudige model, een lineaire model.
Er zijn zelfs nog meer keuzemogelijkheden die je hebt: zo kan je je x-waarden verdelen over bv hoog - midden - laag en voor elk van deze groepen een aparte analyse uitvoeren. Je krijgt dan bv de gesegmenteerde regressie zoals helemaal onderaan beschreven op bovenstaande wiki-pagina (bij het blauwe plaatje). Ook hierdoor wordt de totale foutensom kleiner.
Kortom: in het algemeen kom je het beste uit met het eenvoudigste model, maar je moet in het achterhoofd houden dat er nog andere modellen bestaan, die jouw proces mogelijk beter beschrijven.
Stel we hebben de volgende meetgegevens:
Code: Selecteer alles
x y
1 5
2 6
3 9
Je kan dit doen met regressie-analyse (zie bv http://nl.wikipedia.org/wiki/Regressie-analyse) vergelijkbaar met wat we hierboven gedaan hebben.
Je zoekt dan de lijn y = Ax + B die zo goed mogelijk door de meetpunten gaat.
Je vindt in ons geval y = 2x + 2.67
Als je kijkt naar onze x-waarden vind je de model-waarden ym:
Code: Selecteer alles
x ym
1 4.667
2 6.667
3 8.667
Een rechte lijn waarvoor deze foutensom kleiner is bestaat niet.
Voor deze foutensom is dit de optimale lijn.
Maar niemand zegt dat we verplicht zijn om deze foutenmaat te hanteren. Je zou bijvoorbeeld ook naar de som van (de absolute waarden van) de afstand van elk punt tot de lijn kunnen kijken.
Een tweede punt is: waarom zou het model een lineair model moeten zijn, dus in de vorm ym = Ax + B?
Stel we kiezen een kwadratisch verband: ym = Ax^2 + Bx + C.
Je vindt dan als best passende parabool ym = x^2 - 2x + 6.
De foutensom is nu nul! (ga maar na voor x = 1, 2 en 3)
Hoewel de foutensom nu nul is, hoeft dit echter niet het model te zijn dat het proces dat je bestudeert het beste beschrijft. Als je bijvoorbeeld meer meetpunten zou hebben, zou er heel goed uit kunnen komen dat de beste rechte lijn dan toch beter past dan de beste parabool.
Als je domeinkennis hebt, dus weet volgens welk verband je proces verloopt, bv lineair, kwadratisch, exponentieel etc, dan kies je natuurlijk dat betreffende model.
Weet je het niet, dan kies je doorgaans het meest eenvoudige model, een lineaire model.
Er zijn zelfs nog meer keuzemogelijkheden die je hebt: zo kan je je x-waarden verdelen over bv hoog - midden - laag en voor elk van deze groepen een aparte analyse uitvoeren. Je krijgt dan bv de gesegmenteerde regressie zoals helemaal onderaan beschreven op bovenstaande wiki-pagina (bij het blauwe plaatje). Ook hierdoor wordt de totale foutensom kleiner.
Kortom: in het algemeen kom je het beste uit met het eenvoudigste model, maar je moet in het achterhoofd houden dat er nog andere modellen bestaan, die jouw proces mogelijk beter beschrijven.
Re: Belangrijke opdracht
Wanneer ik dit nu bepaal bekom ik negatieve waarden. Maar het is eigenlijk de bedoeling dat ik overal positieve waarden bekom, zodat ik deze dan in procenten kan uitdrukken. Heeft u hier een oplossing voor?
Re: Belangrijke opdracht
Volgens mij heb je nu A, B, C en D uit je vergelijking:
y = A*t1 + B*t2 + C*t3 + D*t4
waarbij y een voorspelling is voor de werkelijke waarde
verbruik*(t1+t2+t3+t4) = w
Als je het verschil bekijkt tussen y en w zal dit negatief, nul of positief zijn: je zal ofwel te hoog, ofwel goed, ofwel te laag voorspellen.
Hetzelfde geldt voor het relatieve verschil
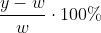
Wil je een positief percentage in de afwijking van y ten opzichte van w, dan neem je de absolute waarde van het verschil:
}{w} \cdot 100\%)
Voorbeeld:
Stel je gevonden waarde w = 200.
Als je voorspelde waarde y = 204, dan is het relatieve verschil ((204-200)/200)*100% = 2%: je zit met je voorspelling 2% te hoog.
Als je voorspelde waarde y = 190, dan is het relatieve verschil ((190-200)/200)*100% = -5%: je zit met je voorspelling 5% te laag.
Gebruik je de absolute waarde, dan worden beide percentages positief:
(abs(204-200)/200)*100% = 2%
(abs(190-200)/200)*100% = 5%
want abs(-10)=10.
Je ziet in dit laatste geval dus alleen hoeveel procent je voorspelling afwijkt van de werkelijke waarde, maar niet meer of je te hoog of te laag zit.
Bedoel je dit?
y = A*t1 + B*t2 + C*t3 + D*t4
waarbij y een voorspelling is voor de werkelijke waarde
verbruik*(t1+t2+t3+t4) = w
Als je het verschil bekijkt tussen y en w zal dit negatief, nul of positief zijn: je zal ofwel te hoog, ofwel goed, ofwel te laag voorspellen.
Hetzelfde geldt voor het relatieve verschil
Wil je een positief percentage in de afwijking van y ten opzichte van w, dan neem je de absolute waarde van het verschil:
Voorbeeld:
Stel je gevonden waarde w = 200.
Als je voorspelde waarde y = 204, dan is het relatieve verschil ((204-200)/200)*100% = 2%: je zit met je voorspelling 2% te hoog.
Als je voorspelde waarde y = 190, dan is het relatieve verschil ((190-200)/200)*100% = -5%: je zit met je voorspelling 5% te laag.
Gebruik je de absolute waarde, dan worden beide percentages positief:
(abs(204-200)/200)*100% = 2%
(abs(190-200)/200)*100% = 5%
want abs(-10)=10.
Je ziet in dit laatste geval dus alleen hoeveel procent je voorspelling afwijkt van de werkelijke waarde, maar niet meer of je te hoog of te laag zit.
Bedoel je dit?
Re: Belangrijke opdracht
Nee, ik bedoel het volgende:
mijn bedoeling is om bijvoorbeeld het verbruik van een bepaald onderdeel van een autorit te schatten. Laat ons bijvoorbeeld zeggen dat t1 het tijdstip is dat de auto 30km/u rijdt, t2 het tijdstip dat de auto 50 rijdt, t3 70 enz.. Dan zou ik verwachten dat in de vergelijking A*t1+B*t2+C*t3+...=v*(t1+t2+t3+..), A B en C percentages zullen weergeven van het totale verbruik. Maar nu bekom ik logischerwijs de best aansluitende curve, maar bekom ik daarbij wel een A van -2000 een B van 3000 waar ik in mijn berekeningen niet verder met kan.
mijn bedoeling is om bijvoorbeeld het verbruik van een bepaald onderdeel van een autorit te schatten. Laat ons bijvoorbeeld zeggen dat t1 het tijdstip is dat de auto 30km/u rijdt, t2 het tijdstip dat de auto 50 rijdt, t3 70 enz.. Dan zou ik verwachten dat in de vergelijking A*t1+B*t2+C*t3+...=v*(t1+t2+t3+..), A B en C percentages zullen weergeven van het totale verbruik. Maar nu bekom ik logischerwijs de best aansluitende curve, maar bekom ik daarbij wel een A van -2000 een B van 3000 waar ik in mijn berekeningen niet verder met kan.
Re: Belangrijke opdracht
Dat is vreemd.
Kloppen de eenheden van je meetwaarden?
Bv: alle t in minuten,
A, B, C, D en v in liter/minuut?
Kan het zijn dat je v al in liters hebt (dan hoef je niet meer met (t1+t2+t3+t4) te vermenigvuldigen.
Voorbeeld met wat meer realistische waarden:
Stel je auto heeft het volgende verbruik bij 4 snelheden in km/uur:
In de laatste kolom staan dan de waarden van A, B, C en D die je zoekt.
Vervolgens:
Noem t50 het aantal minuten dat je 50 km/uur rijdt,
noem t70 het aantal minuten dat je 70 km/uur rijdt,
etc
dan verwacht je voor onderstaande voorbeeldcombinaties het volgende verbruik v in liters:
Als je de waarden uit deze tabel gebruikt, dan moet je via de methode uit mijn eerdere posts vrijwel exact de waarden van A, B, C en D kunnen terugvinden (NB: het verbuik v is in liters, niet in liters per minuut, je hoeft v nu dus niet meer met (t1+..+t4) te vermenigvuldigen).
Lukt je dat?
Nu zullen er in de werkelijke wereld allerhande verstoringen zijn (hoe lang is je motor koud, hoeveel tegenwind, hoe vaak stoppen en optrekken etc). Hierdoor zullen de gemeten waarden afwijken van de theoretische waarden. Je verwacht alleen niet dat je verbruikswaarden A, B, C en D negatief worden, zeker omdat je zo veel gegevens gemeten hebt (je schreef eerder dat je 100 van deze vergelijkingen hebt).
Kan je in dit voorbeeld mbv de laatste tabel de vector
[0.052076, 0.064818, 0.074985, 0.10786]
terugvinden?
Kloppen de eenheden van je meetwaarden?
Bv: alle t in minuten,
A, B, C, D en v in liter/minuut?
Kan het zijn dat je v al in liters hebt (dan hoef je niet meer met (t1+t2+t3+t4) te vermenigvuldigen.
Voorbeeld met wat meer realistische waarden:
Stel je auto heeft het volgende verbruik bij 4 snelheden in km/uur:
Code: Selecteer alles
snelh km/l liter/uur liter/min
50 16 3.1250 0.05208
70 18 3.8889 0.06481
90 20 4.5000 0.07500
110 17 6.4706 0.10784
Vervolgens:
Noem t50 het aantal minuten dat je 50 km/uur rijdt,
noem t70 het aantal minuten dat je 70 km/uur rijdt,
etc
dan verwacht je voor onderstaande voorbeeldcombinaties het volgende verbruik v in liters:
Code: Selecteer alles
t50 t70 t90 t110 v
30 50 40 20 9.96
45 90 16 33 12.94
60 10 20 90 14.98
10 15 40 150 20.67
110 200 20 0 20.19Lukt je dat?
Nu zullen er in de werkelijke wereld allerhande verstoringen zijn (hoe lang is je motor koud, hoeveel tegenwind, hoe vaak stoppen en optrekken etc). Hierdoor zullen de gemeten waarden afwijken van de theoretische waarden. Je verwacht alleen niet dat je verbruikswaarden A, B, C en D negatief worden, zeker omdat je zo veel gegevens gemeten hebt (je schreef eerder dat je 100 van deze vergelijkingen hebt).
Kan je in dit voorbeeld mbv de laatste tabel de vector
[0.052076, 0.064818, 0.074985, 0.10786]
terugvinden?
Re: Belangrijke opdracht
Ja, de waarden kloppen. Mijn tijden staan in uren, en het verbruik in liter.. Ik snap niet wat ik fout doe.
Wanneer ik uw oefening nareken kom ik wel dezelfde waarden uit, dus in de bewerking kan het volgens mij niet fout lopen.
Maar wanneer ik de matrices met mijn rekenmachine uitreken komt deze altijd zeggen 'singular mat' en kan ik dus niet verder, kan dat daar iets met te maken hebben? Met het programmatje op mijn computer heb ik er geen problemen mee, behalve de negatieve waarden dan
Wanneer ik uw oefening nareken kom ik wel dezelfde waarden uit, dus in de bewerking kan het volgens mij niet fout lopen.
Maar wanneer ik de matrices met mijn rekenmachine uitreken komt deze altijd zeggen 'singular mat' en kan ik dus niet verder, kan dat daar iets met te maken hebben? Met het programmatje op mijn computer heb ik er geen problemen mee, behalve de negatieve waarden dan
Re: Belangrijke opdracht
In de formule
is dan
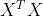
singulier, waardoor je de inverse
^{-1})
niet kan bepalen.
Dat is zeldzaam.
Als X bij jou een 100 bij 4 matrix is, dan is een 4 bij 4 matrix.
Wat zijn de 16 getallen van voor jouw experiment?
PS: je mag ook X en y posten (of via een privebericht versturen als je ze liever niet openbaar maakt).
is dan
singulier, waardoor je de inverse
niet kan bepalen.
Dat is zeldzaam.
Als X bij jou een 100 bij 4 matrix is, dan is
Wat zijn de 16 getallen van
PS: je mag ook X en y posten (of via een privebericht versturen als je ze liever niet openbaar maakt).
Re: Belangrijke opdracht
X is bij jou een matrix met 14 rijen en 13 kolommen.
Je zoekt dan de constanten b1 t/m b13 voor je model:
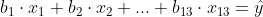
Als je hierin je meetwaarden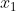 t/m
t/m 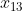 invult, wil je hieruit een voorspelde waarde
invult, wil je hieruit een voorspelde waarde 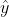 krijgen die steeds zo dicht mogelijk de werkelijke waarde van
krijgen die steeds zo dicht mogelijk de werkelijke waarde van 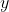 benadert.
benadert.
Voor jouw matrix X en vector Y kom ik uit op
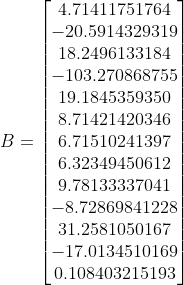
ofwel (eenvoudiger te kopieren):
B = [4.71411751764, -20.5914329319, 18.2496133184, -103.270868755, 19.1845359350, 8.71421420346, 6.71510241397, 6.32349450612, 9.78133337041, -8.72869841228, 31.2581050167, -17.0134510169, 0.108403215193]^T
Als je nu het matrixproduct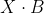 berekent, zie je dat je vrij goed op de waardes van Y uitkomt (is dat bij jou ook zo?).
berekent, zie je dat je vrij goed op de waardes van Y uitkomt (is dat bij jou ook zo?).
Hoe jij op jouw resultaatvector uit kon komen weet ik niet, mogelijk spelen er nauwkeurigheidsproblemen bij de berekening van de inverse van . Dit is overigens geen singuliere matrix, de determinant is ongeveer 1.24441673090*10^16, de inverse bestaat dan.
. Dit is overigens geen singuliere matrix, de determinant is ongeveer 1.24441673090*10^16, de inverse bestaat dan.
Het kan ook zijn dat je rekenmachine of programma (waar werk je mee?) matrices van dergelijk omvang niet goed aankan.
Nog een optie: heb je het mogelijk eerst geprobeerd met minder vergelijkingen dan onbekenden (dan gaat het ook mis)?
Als je wil weten welke waarden het belangrijkst zijn voor de bepaling van de geschatte waarde van y, dan kan je voor elk van de 13 kolommen van X de gemiddelde waarde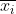 van kolom i bepalen en die waarde vermenigvuldigen met de bijbehorende
van kolom i bepalen en die waarde vermenigvuldigen met de bijbehorende 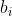 .
.
Hoe groter het product (in absolute zin), hoe groter de bijdrage van die kolom aan het eindresultaat.
(in absolute zin), hoe groter de bijdrage van die kolom aan het eindresultaat.
Een laatste punt: je hebt hier een lineair model dat op basis van de huidige waarden van X en Y de beste resultaten geeft om toekomstige waarden van y voor gegeven x1 t/m x13 te voorspellen.
Als je wil dat alle waarden in B niet-negatief zijn, dan zal het model minder goed worden (tov de standaard foutmaat).
Laat het svp even weten als je dit wil, dan zal ik ook verder zoeken, ik weet zo niet of hier standaard technieken voor bestaan. Wel een leuk probleem overigens.
Het kan ook zijn dat de waarden van B vanzelf allemaal niet-negatief worden zodra je wat meer meetwaarden (= regels in X) hebt: 14 regels voor 13 onbekenden is wel erg marginaal.
PS:
Met dit laatste bedoel ik dit:
als je matrix vierkant is (als je 1 regel uit jouw X weglaat) los je in feite een (minimaal) stelsel op van 13 vergelijkingen met 13 onbekenden:
^{-1}X^TY)
mag je dan herschrijven als (X is inverteerbaar, dus X^T ook):
^{-1}X^TY = X^{-1} Y)
ofwel

Voorbeeld:
Neem

dan is
^{-1}X^TY = \begin{bmatrix}-1\\2\end{bmatrix})
en is XB exact gelijk aan Y.
Merk ook op dat b1 in dit geval negatief is, namelijk -1.
In je model levert dit dus:
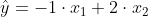
Die negatieve waarde kan veroorzaakt zijn door toeval bij deze zeer kleine steekproefomvang: je hebt slechts 2 vergelijkingen met 2 onbekenden.
Als je naast deze 2 waarnemingen nog een derde waarneming had gehad, bijvoorbeeld:
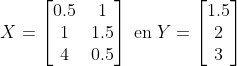
dan vind je:
^{-1}X^TY \approx \begin{bmatrix}0.62\\1.00\end{bmatrix})
Nu zijn alle waarden van B positief, hetgeen je mogelijk theoretisch verwacht bij het systeem wat je model beschrijft.
Je hebt nu het model:
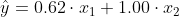
met als best mogelijke benadering van Y:

Je ziet dat dit niet meer exact gelijk is aan Y, maar je model
zal de werkelijkheid beter benaderen.
In het algemeen: hoe meer waarnemingen (= regels in X en Y) je hebt, hoe beter je model zal zijn.
Je zoekt dan de constanten b1 t/m b13 voor je model:
Als je hierin je meetwaarden
Voor jouw matrix X en vector Y kom ik uit op
ofwel (eenvoudiger te kopieren):
B = [4.71411751764, -20.5914329319, 18.2496133184, -103.270868755, 19.1845359350, 8.71421420346, 6.71510241397, 6.32349450612, 9.78133337041, -8.72869841228, 31.2581050167, -17.0134510169, 0.108403215193]^T
Als je nu het matrixproduct
Hoe jij op jouw resultaatvector uit kon komen weet ik niet, mogelijk spelen er nauwkeurigheidsproblemen bij de berekening van de inverse van
Het kan ook zijn dat je rekenmachine of programma (waar werk je mee?) matrices van dergelijk omvang niet goed aankan.
Nog een optie: heb je het mogelijk eerst geprobeerd met minder vergelijkingen dan onbekenden (dan gaat het ook mis)?
Als je wil weten welke waarden het belangrijkst zijn voor de bepaling van de geschatte waarde van y, dan kan je voor elk van de 13 kolommen van X de gemiddelde waarde
Hoe groter het product
Een laatste punt: je hebt hier een lineair model dat op basis van de huidige waarden van X en Y de beste resultaten geeft om toekomstige waarden van y voor gegeven x1 t/m x13 te voorspellen.
Als je wil dat alle waarden in B niet-negatief zijn, dan zal het model minder goed worden (tov de standaard foutmaat).
Laat het svp even weten als je dit wil, dan zal ik ook verder zoeken, ik weet zo niet of hier standaard technieken voor bestaan. Wel een leuk probleem overigens.
Het kan ook zijn dat de waarden van B vanzelf allemaal niet-negatief worden zodra je wat meer meetwaarden (= regels in X) hebt: 14 regels voor 13 onbekenden is wel erg marginaal.
PS:
Met dit laatste bedoel ik dit:
als je matrix vierkant is (als je 1 regel uit jouw X weglaat) los je in feite een (minimaal) stelsel op van 13 vergelijkingen met 13 onbekenden:
mag je dan herschrijven als (X is inverteerbaar, dus X^T ook):
ofwel
Voorbeeld:
Neem
dan is
en is XB exact gelijk aan Y.
Merk ook op dat b1 in dit geval negatief is, namelijk -1.
In je model levert dit dus:
Die negatieve waarde kan veroorzaakt zijn door toeval bij deze zeer kleine steekproefomvang: je hebt slechts 2 vergelijkingen met 2 onbekenden.
Als je naast deze 2 waarnemingen nog een derde waarneming had gehad, bijvoorbeeld:
dan vind je:
Nu zijn alle waarden van B positief, hetgeen je mogelijk theoretisch verwacht bij het systeem wat je model beschrijft.
Je hebt nu het model:
met als best mogelijke benadering van Y:
Je ziet dat dit niet meer exact gelijk is aan Y, maar je model
zal de werkelijkheid beter benaderen.
In het algemeen: hoe meer waarnemingen (= regels in X en Y) je hebt, hoe beter je model zal zijn.
Re: Belangrijke opdracht
Het is inderdaad de bedoeling dat alle waarden positief uitkomen, aangezien het de bedoeling is te achterhalen wat het percentage is van het volledige brandstofverbruik per deeltje. Dan is lineair toch de enige mogelijke oplossing? Of ben ik verkeerd? Ik ga deze middag eens kijken waar de fout juist zit in mijn berekening..
Re: Belangrijke opdracht
Ik reken dit uit in excel (en wou het eens narekenen met m'n rekenmachine). Maar de waarden die ik uitkom voor B zijn toch wel erg verschillend dan degene die jij bekomt. Toch komen Y en Y^ relatief goed overeen als ik Y^-Y doe bekom ik:
0,104614247
0,026251349
-0,270959258
0,412331049
-0,295236008
-0,31823983
2,611364278
-2,067307094
-0,981264806
2,250913282
-0,341549612
0,651906895
-0,270556702
-1,48249394
En voor B bekom ik:
819,79
-3513,16
3823,87
-18008,85
3160,63
1662,73
468,90
180,86
1784,77
-1498,67
5253,19
-2864,29
18,25
Ik zal ondertussen nog eens luisteren voor meer waarden te bekomen.. Misschien dat dan inderdaad het probleem zichzelf oplost.
0,104614247
0,026251349
-0,270959258
0,412331049
-0,295236008
-0,31823983
2,611364278
-2,067307094
-0,981264806
2,250913282
-0,341549612
0,651906895
-0,270556702
-1,48249394
En voor B bekom ik:
819,79
-3513,16
3823,87
-18008,85
3160,63
1662,73
468,90
180,86
1784,77
-1498,67
5253,19
-2864,29
18,25
Ik zal ondertussen nog eens luisteren voor meer waarden te bekomen.. Misschien dat dan inderdaad het probleem zichzelf oplost.