X is bij jou een matrix met 14 rijen en 13 kolommen.
Je zoekt dan de constanten b1 t/m b13 voor je model:
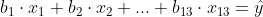
Als je hierin je meetwaarden
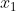
t/m
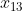
invult, wil je hieruit een voorspelde waarde
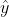
krijgen die steeds zo dicht mogelijk de werkelijke waarde van
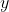
benadert.
Voor jouw matrix X en vector Y kom ik uit op
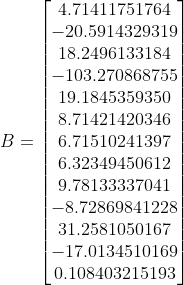
ofwel (eenvoudiger te kopieren):
B = [4.71411751764, -20.5914329319, 18.2496133184, -103.270868755, 19.1845359350, 8.71421420346, 6.71510241397, 6.32349450612, 9.78133337041, -8.72869841228, 31.2581050167, -17.0134510169, 0.108403215193]^T
Als je nu het matrixproduct
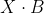
berekent, zie je dat je vrij goed op de waardes van Y uitkomt (
is dat bij jou ook zo?).
Hoe jij op jouw resultaatvector uit kon komen weet ik niet, mogelijk spelen er nauwkeurigheidsproblemen bij de berekening van de inverse van

. Dit is overigens geen singuliere matrix, de determinant is ongeveer 1.24441673090*10^16, de inverse bestaat dan.
Het kan ook zijn dat je rekenmachine of programma (waar werk je mee?) matrices van dergelijk omvang niet goed aankan.
Nog een optie: heb je het mogelijk eerst geprobeerd met minder vergelijkingen dan onbekenden (dan gaat het ook mis)?
Als je wil weten welke waarden het belangrijkst zijn voor de bepaling van de geschatte waarde van y, dan kan je voor elk van de 13 kolommen van X de gemiddelde waarde
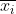
van kolom i bepalen en die waarde vermenigvuldigen met de bijbehorende
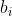
.
Hoe groter het product

(in absolute zin), hoe groter de bijdrage van die kolom aan het eindresultaat.
Een laatste punt: je hebt hier een lineair model dat op basis van de huidige waarden van X en Y de beste resultaten geeft om toekomstige waarden van y voor gegeven x1 t/m x13 te voorspellen.
Als je wil dat alle waarden in B niet-negatief zijn, dan zal het model minder goed worden (tov de standaard foutmaat).
Laat het svp even weten als je dit wil, dan zal ik ook verder zoeken, ik weet zo niet of hier standaard technieken voor bestaan. Wel een leuk probleem overigens.
Het kan ook zijn dat de waarden van B vanzelf allemaal niet-negatief worden zodra je wat meer meetwaarden (= regels in X) hebt: 14 regels voor 13 onbekenden is wel erg marginaal.
PS:
Met dit laatste bedoel ik dit:
als je matrix vierkant is (als je 1 regel uit jouw X weglaat) los je in feite een (minimaal) stelsel op van 13 vergelijkingen met 13 onbekenden:
^{-1}X^TY)
mag je dan herschrijven als (X is inverteerbaar, dus X^T ook):
^{-1}X^TY = X^{-1} Y)
ofwel
 Voorbeeld:
Voorbeeld:
Neem

dan is
^{-1}X^TY = \begin{bmatrix}-1\\2\end{bmatrix})
en is XB exact gelijk aan Y.
Merk ook op dat b1 in dit geval negatief is, namelijk -1.
In je model levert dit dus:
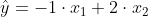
Die negatieve waarde kan veroorzaakt zijn door toeval bij deze zeer kleine steekproefomvang: je hebt slechts 2 vergelijkingen met 2 onbekenden.
Als je naast deze 2 waarnemingen nog een derde waarneming had gehad, bijvoorbeeld:
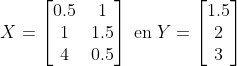
dan vind je:
^{-1}X^TY \approx \begin{bmatrix}0.62\\1.00\end{bmatrix})
Nu zijn alle waarden van B positief, hetgeen je mogelijk theoretisch verwacht bij het systeem wat je model beschrijft.
Je hebt nu het model:
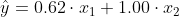
met als best mogelijke benadering van Y:

Je ziet dat dit niet meer exact gelijk is aan Y, maar je model
zal de werkelijkheid beter benaderen.
In het algemeen: hoe meer waarnemingen (= regels in X en Y) je hebt, hoe beter je model zal zijn.